
티스토리 뷰
파서는 우리가 많이 쓰면서도 정확하게 그 알고리즘을 알지 못하는 대표적인 방법 중 하나입니다. 컴파일러의 한 분야이고 알아야 하는 용어가 많아서 쉽게 이해하기 어려운 분야입니다. 여기서는 완전 처음부터 자바만 가지고 파서를 구현하는 방법을 알아보려고 합니다. 물론 문맥무관문법(CFG: Context-Free Grammar)나 토큰, 어휘분석기의 개념 등을 알고 있어야 하지만 대략의 개념만 이해한다면 파서의 알고리듬과 구현 코드까지도 들여다 볼 수 있습니다. 함께 출발해 봅시다.
먼저 문법에 대한 간단한 설명입니다. 문맥무관문법은 생성규칙이라는 걸 가지고 왼쪽에 넌터미널 심볼이 나오고 오른쪽에 여러 개의 심볼이 연속해서 나타납니다. 그래서 시작심볼에서 시작해서 차례로 생성규칙을 적용해 가다보면 입력을 처리해서 파스 트리라는 것이 만들어집니다. 다음은 그런 예를 하나 보여줍니다. 괄호와 +. - 연산으로 연결된 수식을 얼마든지 받아들여 트리 형태로 만들어줄 수 있는 문법입니다. (이것은 확장 CGF라고 해서 { ... } 부분이 반복을 나타냅니다.)
E -> T { ('+' | '-') T }
T -> num | '(' E ')'이 문법을 이용해서 다음과 같은 입력을 처리(파싱)할 수 있습니다.
3 + (5 - 4) - (2 + (3 + 4))

오른 쪽의 그림과 같은 파스 트리가 얻어집니다. 파싱이란 문법과 입력이 주어졌을 때 입력의 구조를 문법으로 분석하여 트리 형태의 자료구조로 바꾸어주는 알고리즘이라고 볼 수 있습니다. 파싱은 꼭 트리 형태의 데이터를 만들어낼 필요는 없습니다. 트리와 같은 구조로 분석하면서 데이터를 계산하거나 변환하거나 다른 자료구조로 바꾸는 일을 할 수도 있습니다.
그럼 어떻게 위의 문법에서 이런 트리 구조 또는 수식의 결과를 계산하는 파서를 만들 수 있을까요? 이제 본격적으로 파서를 만드는 일을 살펴봅시다.
파서를 설명하기 전에 어휘(토큰)의 개념을 알아야 합니다. 문법에는 입력에 나타날 수 있는 스트링의 모양들이 정해져 있습니다. 이것을 터미널 심볼이라고 하고 위의 문법에서는 num, +, -, (, ) 같은 스트링들이 정의되어 있습니다.
여기서 num은 숫자로 이루어진 스트링을 의미하고 나머지는 기호로 한 글자씩을 가집니다. 이것을 토큰이라고 하고 입력에서 이러한 토큰들을 잘라내는 것을 어휘분석기라고 합니다. 이에 대해서는 앞의 글에서 lex라는 툴을 사용하는 방법을 살펴보았습니다.
여기서는 파서에 대한 것에 집중하기 위해 토큰은 그냥 Scanner.next()로 받아오는 단위라고 생각해 보겠습니다. 그럼 위의 입력이 토큰마다 빈칸을 가지도록 입력되어야 하겠지요. 이러한 토큰을 처리하는 토큰 클래스라는 것을 정의해 보겠습니다.
class Token {
static final int NUM = 0;
static final int PLUS = 1;
static final int MINUS = 2;
static final int LPAREN = 3;
static final int RPAREN = 4;
static final int EOF = 5;
static final int ERROR = -1;
String tok = null;
int tokNum = EOF;
int getInt() {
if (tokNum != NUM)
throw new RuntimeException("Not a Integer Token");
return Integer.parseInt(tok);
}
void getNext(Scanner scan) {
tok = scan.next();
if (tok.matches("[0-9]+"))
tokNum = Token.NUM;
else {
switch (tok.charAt(0)) {
case '+': tokNum = Token.PLUS;break;
case '-': tokNum = Token.MINUS;break;
case '*': tokNum = Token.MUL;break;
case '/': tokNum = Token.DIV;break;
case '(': tokNum = Token.LPAREN;break;
case ')': tokNum = Token.RPAREN;break;
case '$': tokNum = Token.EOF;break;
default:
throw new RuntimeException("error token");
}
}
System.out.printf("Token: %s\n", this);
}
boolean is(int tokN) {
return tokNum == tokN;
}
@Override
public String toString() {
return String.format("%s (%d)", tok, tokNum);
}
};이 토큰 클래스는 토큰 스트링과 토큰의 번호를 가지는데, 토큰 심볼을 하나씩 읽어들이는 메소드 getNext()를 가지고 그 외에 비교메소드 is()와 NUM인 경우 숫자값으로 변환해 주는 getInt() 메소드를 가집니다.
그럼 이제 우리는 Recursive Descent Parser(RDP)를 만들기 위한 준비를 마쳤습니다. 문법이 주어졌고 어휘를 처리하는 Token 클래스가 있을 때 우리는 문법에 대응하는 파서를 다음과 같이 만들 수 있습니다.
public class RDParser {
Token token = null;
public static void main(String[] args) {
// TODO Auto-generated method stub
RDParser parser = new RDParser();
parser.parse();
}
void parse() {
System.out.print(">> ");
token = Token.nextToken(token);
int rval = E();
System.out.println("결과 : " + rval);
}
int E() {
int rval;
int value = 0;
value = T();
while (true) {
if (!token.is(Token.PLUS) && !token.is(Token.MINUS))
break;
Token prevOp = token;
token = Token.nextToken(token);
rval = T();
if (prevOp.is(Token.PLUS)) {
System.out.printf("%d + %d = %d\n", value, rval, value+rval);
value += rval;
} else if (prevOp.is(Token.MINUS)) {
System.out.printf("%d - %d = %d\n", value, rval, value-rval);
value -= rval;
}
}
return value;
}
int T() {
int value = 0;
if (token.is(Token.NUM)) {
value = token.getInt();
} else if (token.is(Token.LPAREN)) {
token = Token.nextToken(token);
value = E();
}
token = Token.nextToken(token); // 정상 파싱 후 다음 토큰을 읽음
return value;
}
}이 코드는 parse()라는 메소드에서 시작해서 E()와 T()를 차례로 부르면서 위의 그림에 있는 파스트리와 같은 구조를 차례로 (선방문 순서로) 방문하게 됩니다.
이 클래스는 parse라는 메소드를 시작으로 해서 문법의 각 넌터미널에 대응하는 메소드를 가집니다. 그리고 각 메소드는 수식을 계산하기 위해 파싱된 부분의 수식을 계산한 반환값을 int로 가집니다.
각 메소드는 자신의 생성규칙을 적용하여 트리를 만드는 일을 합니다. 그리고 더이상 생성규칙을 적용할 수 없으면 리턴합니다. (그 때까지의 결과값을 반환함)
이 파서 코드의 특징은 E -> T { (+ | -) T } 의 { ... } 반복부를 처리하기 위해 다음 토큰을 미리 하나 읽는 것입니다. +나 -가 나오는 동안 계속 반복을 해야 되고 그것이 아니면 리턴해야 합니다. 즉 )나 $가 나오면 T가 끝나고 E도 끝나고 트리의 부모 노드로 올라가야 되는 거지요. 그래서 E()와 T() 메소드는 다음 토큰을 한 개 더 읽고 리턴하도록 구성되어 있습니다.
이 과정을 그림으로 나타내면 다음과 같습니다. 아래 그림에서 빨간 글씨는 파싱이 된 심볼들을 보여주고 회색 배경의 터미널 노드는 유도된 생성규칙에서 아직 처리되지 않은 남은 부분을 나타냅니다.
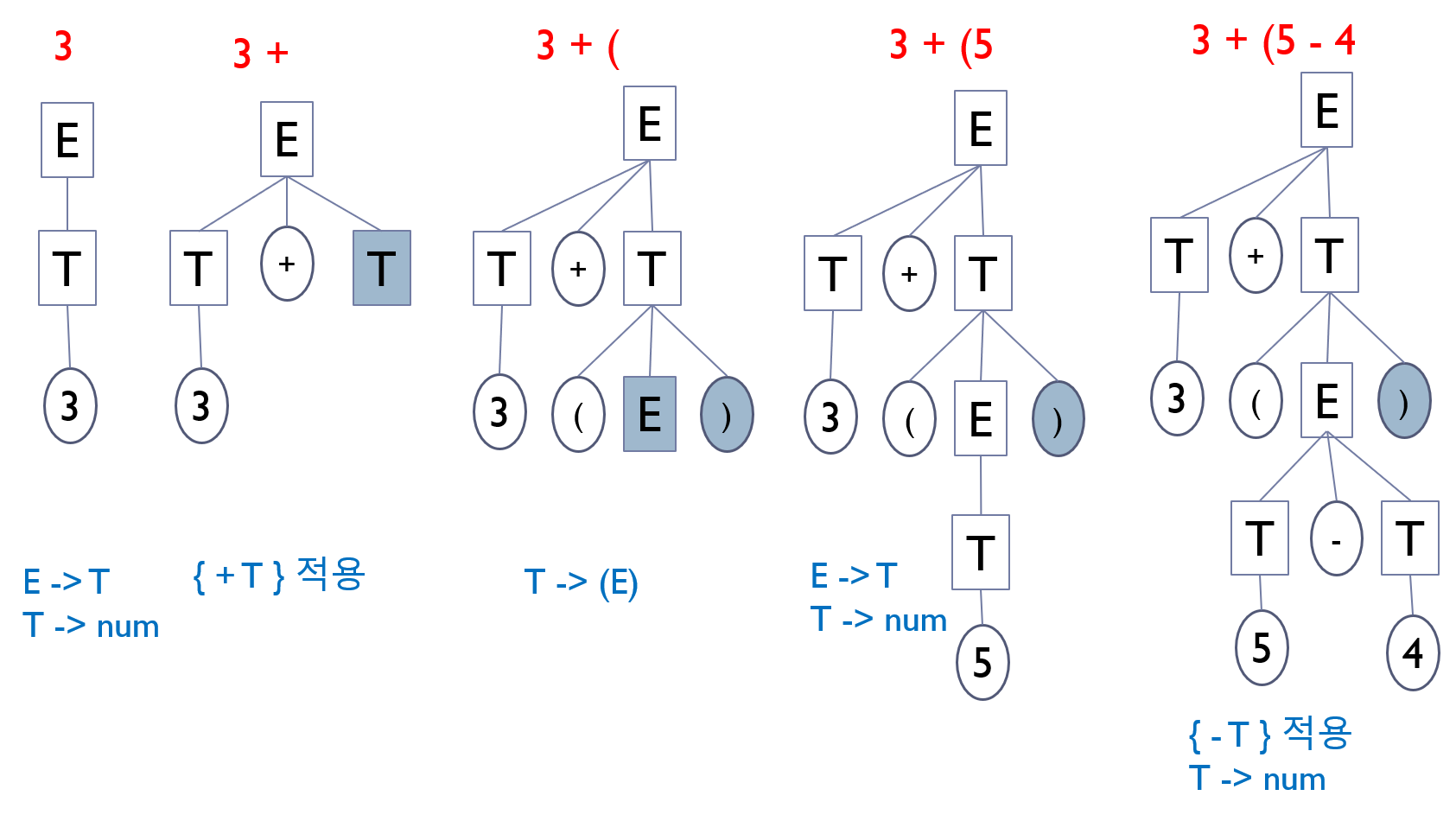
이와 같이 각 메소드가 문법의 생성규칙을 하나씩 적용하고 처리하면 리턴하는 방식으로 트리가 구성되어 가게 됩니다. 이 파서에서는 트리를 만들지는 않지만 트리 형태의 노드들을 거치면서 계산을 수행함을 알 수 있습니다.

여기서는 간단한 +와 - 수식을 이용해서 RDP를 작성하는 방법을 살펴보았습니다.
다음 글에서는 문법을 확장하여 다른 연산자도 처리할 수 있게 만드는 방법을 살펴보겠습니다.
'컴파일러 - regex와 cfg' 카테고리의 다른 글
| LL(1) 파싱 알고리듬 - 파싱 테이블과 파싱 방법 (0) | 2019.12.21 |
|---|---|
| Parser from scratch (2) - Recursive Descent Parser (0) | 2019.12.20 |
| lex 예제 (2) (0) | 2019.10.27 |
| lex를 이용한 어휘분석기 예제 (1) (1) | 2019.10.27 |
| lex 설치와 사용법 (0) | 2019.10.27 |
- Total
- Today
- Yesterday
- 스트링
- TypeError
- 자바regex
- ToString
- APPEND
- contentEquals
- 콜렉션
- typedef
- Camel Style
- format
- 스트링 +
- indexof
- max
- CompareTo
- 이터레이터
- C++ 클래스
- zip
- comparable
- python example
- 동적바인딩
- Lazy evaluation
- Iterator
- rust
- 지연계산
- follow
- python exercise
- 이터러블
- sort key
- contains
- 패턴
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |